![]()
Suche

You are here
Video Super Resolution
Contact:
Background:
The chip of a video camera records the averages of light falling into its pixel sensors. Video details finer than the pixel grid are lost in this process, due to the limited resolution. However, a video usually features a significant amount of redundant information: A single object, say a coffee mug, might move through the video in several seconds, generating hundreds of viewpoints of the mug from slightly different angles. Interestingly these angles usually do not perfectly align with the pixel grid of the video camera. The interesting question is now whether we can use these averaged measurements together with the information how the object is moving, to recover finer details than before.
The basic idea of video super resolution is just that. The different view points of a single scene in a video are used to enhance the overall resolution and quality.
Multiframe Motion Coupling for Video Super Resolution
[ Collaboration with Hendrik Dirks (University of Münster) and Daniel Cremers (Technical University of Munich) ]
Code: https://github.com/HendrikMuenster/superResolution
Classical energy minimization approaches first establish a correspondence of the current frame to all its neighbors in some radius and then use this temporal information for enhancement. In this paper we propose the first variational super resolution approach that computes several super resolved frames in one batch optimization procedure by incorporating motion information between the high resolution image frames themselves. As a consequence, the number of motion estimation problems grows linearly in the number of frames, opposed to a quadratic growth of classical methods and temporal consistency is enforced naturally.
We use infimal convolution regularization as well as an automatic parameter balancing scheme to automatically determine the reliability of the motion information and reweight the regularization locally. We demonstrate that our approach yields state-of-the-art results and even is competitive with machine learning approaches.
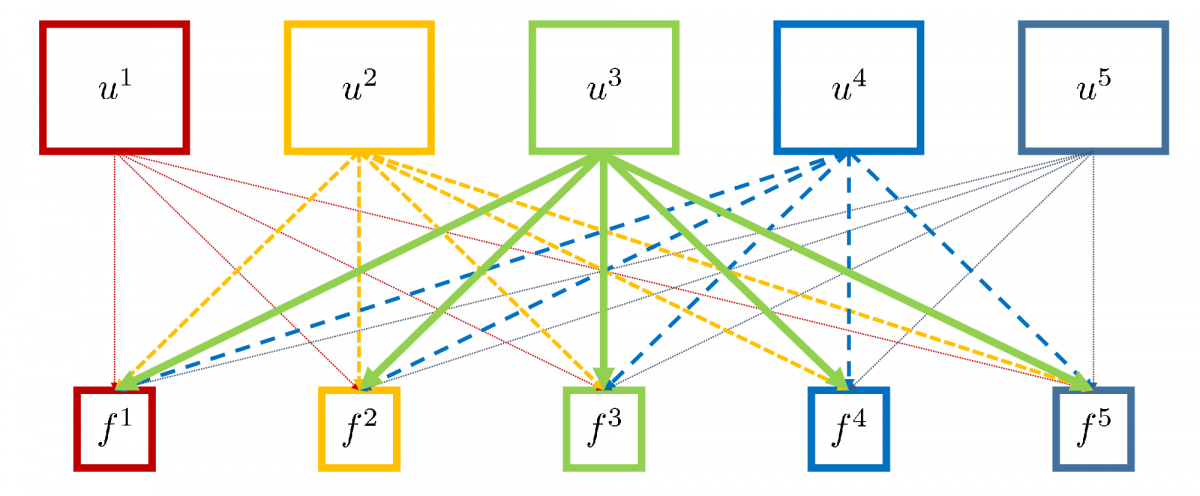
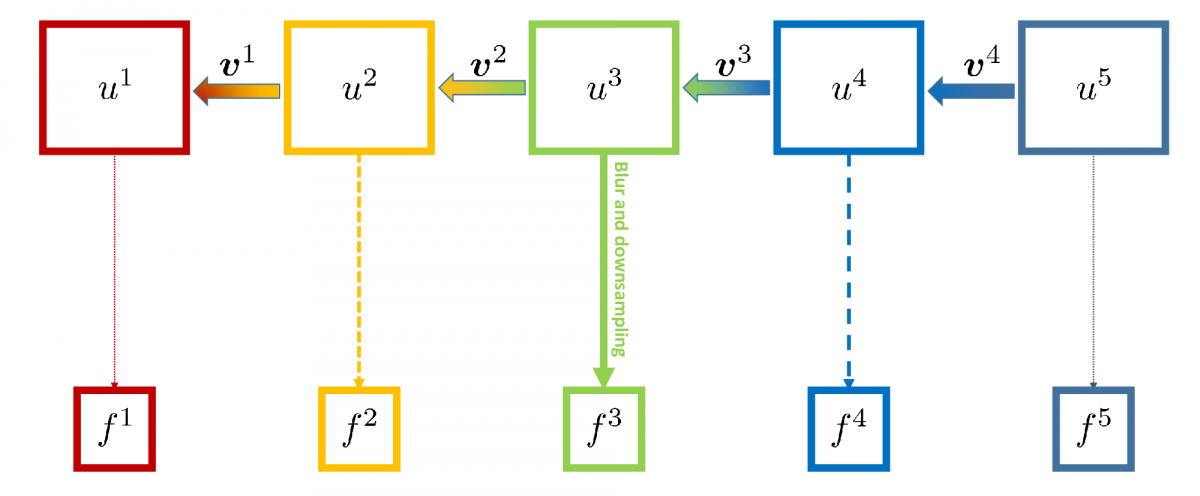
Classical approaches, e.g. Unger et al. ("A convex approach for variational superresolution"), couple all frames as in the left figure. Our approach (on the right) couples all high resolution frames directly.
Infimal Convolution
Another problem in video super resolution is that the optical flow that is used to match frames can often be unreliable. As such it is important that the designed algorithm can automatically determine whether the optical flow is reliable. In our work we use the infimal convolution of temporal (= optical flow) and spatial (= total variation) regularization. This leads to a trade-off between both regularizers, that can be visualized very well. In the following videos, "w" denotes dominantly spatially regularized elements, whereas "u-w" denotes the dominantly temporally regularized elements of the video:
Temporal Consistency
A key feature of visually pleasing videos is temporal consistency. Even if a method generates a sequence of high quality high resolution frames, temporal inconsistencies will be visible as disturbing flickering.
We showcase this effect in the following videos, where we compare nearest neighbors interpolation, bicubic interpolation, VSRnet (Kappeler et al., "Video Super-Resolution With Convolutional Neural Networks"), VDSR (Kim et al. "Accurate Image Super-Resolution Using
Very Deep Convolutional Networks" with our approach for Multiframe Motion Coupling.
Looking at the results, one can see that all three super resolution approaches managed to enhance the visual quality of the input data significantly and clearly outperform bicubic interpolation. While the VDSR algorithm led to very good single frame PSNR values, one can see strong flickering effects and the aliasing contained in the input data is enhanced. While the latter is to be expected considering that VDSR was proposed as an image upsampling method (not necessarily to be used for video super resolution), similar effects are almost equally present in the VSRnet approach (which was developed for video super resolution). We suspect that this flickering is ifficult to suppress for any method that does not couple the output frames temporally.
The proposed approach can reduce the flickering significantly. In the calendar sequence, our approach shows some remaining temporal inconsistencies in the awning of the ”MAREE FINE”. However, all other parts in the central calendar image remain temporally stable in our approach, while the results of the learning based methods contain strong flickering effects. A similar behavior can be observed in the city sequence, which is challenging due to the strong aliasing caused by the bicubic downsampling. While the aliasing of the building appearing left of the central tower could not be removed completely, it is reduced to a small subset of the video right after occlusion by the tower. The competing approaches not only show a significantly stronger aliasing effect, but also exhibit a visually unpleasing flickering in other parts of the sequence, for instance in the brown-beige-colored building appearing right of the central tower.
On the foreman scene our approach is temporally stable throughout the entire sequence, except for a few frames where fast motion causes spatial artifacts in the reconstruction, e.g. when the foreman’s hand flashes into the scene. The VDSR method does not rely on temporal information at all. The VSRnet method, does take neighboring frames into account while adaptively compensating their motion, but seems to rely muss less on such information. The latter leads to being more robust to very quick motions (such as the flashing hand), but also prevents temporal consistency.
To illustrate the lack of temporal consistency, we clip the forman.avi video to the last 80 frames and zoom into the central region, see end of the foreman video.
In conclusion, temporal consistency is extremely important for visually pleasing video super resolution.